Issue #203: Documentation for mod_wsgi has a number of mistakes.
| Reported by: | Graham Dumpleton |
| State: | resolved |
| Created on: | 2016-04-03 03:33 |
| Updated on: | 2016-05-05 14:03 |
Description
Documentation at:
has the following errors.
1 - Two sample mod_wsgi configuration are give of:
WSGIDaemonProcess kallithea \
processes=1 threads=4 \
python-path=/srv/kallithea/venv/lib/python2.7/site-packages
WSGIScriptAlias / /srv/kallithea/dispatch.wsgi
WSGIPassAuthorization On
and
WSGIDaemonProcess kallithea processes=1 threads=4 WSGIScriptAlias / /srv/kallithea/dispatch.wsgi WSGIPassAuthorization On
Both examples are missing the directive:
WSGIProcessGroup kallithea
This is necessary as otherwise although a mod_wsgi daemon process group was defined, requests will not be delegated and run in the mod_wsgi daemon process group. The result will be that things appear to work, but code will be running in the Apache child worker processes. This is not ideal and would actually be a bad idea if using Apache prefork MPM or event MPM with single threaded Apache child worker processes. The result would be way more copies of Kallithea than expect, with potential to run out of memory if Apache decides to spin up more child worker processes.
As well as adding the WSGIProcessGroup directive, recommended that also set:
WSGIRestrictEmbedded On
This turns off initialisation of Python interpreter in Apache child worker processes, saving memory and decreasing startup time of child worker processes.
This latter directive needs to be set out of the VirtualHost at global Apache configuration scope.
2 - The processes=1 option to WSGIDaemonProcess is redundant as that is the default. It is important not to supply it though as by adding it as done that results in wsgi.multiprocess being set False in WSGI environ for requests. This would be an issue if you happened to scale Kallithea across multiple hosts, and something was relying on wsgi.multiprocess being correct. It would be correct if scaled horizontally out to more hosts. The default, of not supplying processes option leaves wsgi.multiprocess as True meaning no potential for issues if scaling out to more hosts.
3 - The statement:
""" Note When running apache as root, please make sure it doesn’t run Kallithea as root, for examply by adding: user=www-data group=www-data to the configuration. """
is wrong.
Even if Apache is started as root so it can bind port 80, neither the child worker processes, or mod_wsgi daemon processes ever run as root. Apache always drops privileges before anything actually runs. As a result, Apache will always run applications as the Apache user, which for many systems is www-data. There is never any need to set user or group to www-data explicitly.
What the note should really say is:
"""
Note: Apache will by default run as a special Apache user, on Linux systems usually www-data. If you need to have the repositories directory owned by a different user, use the user and group options to WSGIDaemonProcess to set the name of the user and group.
"""
4 - If using a Python virtual environment, rather than use the python-path option to specify the location of the Python virtual environment site-packages directory, it is better to use the python-home directory and give it the path to the root of the Python virtual environment. That is, whatever sys.prefix is for the installation.
This negates the need to do Python virtual environment activate in the WSGI script file.
The final configuration you really want to use where using a Python virtual environment is therefore:
WSGIDaemonProcess kallithea \
processes=1 threads=4 \
python-home=/srv/kallithea/venv
WSGIProcessGroup kallithea
WSGIScriptAlias / /srv/kallithea/dispatch.wsgi
WSGIPassAuthorization On
Attachments
Comments
Comment by Mads Kiilerich, on 2016-04-03 17:08
Thank you very much for reaching out to us! That part of the documentation is old and has never been cleaned up. It should probably be heavily copyedited and restructured.
WSGIRestrictedEmbedded seems to be undocumented - it is only mentioned in few posts from you? With Apache/2.2.22 and mod_wsgi/3.3 on debian I get "Invalid command 'WSGIRestrictedEmbedded'"?
It seems surprising (while well documented) that setting processes to the default value is different from not setting it. It could perhaps make sense to let mod_wsgi treat processes=1 as the default and have a special way to "fake" setting wsgi.multiprocess?
A couple of very related questions:
- For Kallithea, clone operations might run for several hours for big repos and slow connections. A graceful apache restart will thus give an interruption of service. Would it be possible to work with Apache to allow existing requests run to completion without the 3 s timeout? Or what do you recommend - how can the application under mod_wsgi be restarted without downtime?
- Can you confirm that shutdown-timeout=BIGVALUE should allow existing requests to run to finish without interruption of service, also when using multiple threads and maximum-requests or when using WSGIScriptReloading or similar?
Comment by Graham Dumpleton, on 2016-04-03 20:32
That should have been WSGIRestrictEmbedded. Have fixed.
Comment by Mads Kiilerich, on 2016-04-03 21:05
Thanks. I pushed https://kallithea-scm.org/repos/kallithea/changeset/8c479b274e0370e70d64614ff630620a1d0d952a , and http://kallithea.readthedocs.org/en/stable/setup.html is updated. Please let us know if that is ok or if you have more comments.
Also, please advice on the issue with restarting.
Comment by Graham Dumpleton, on 2016-04-03 21:19
Thanks.
There is though a trailing triple quote left on lines about Apache user.
I will comment more on long running tasks later. Still have to work through myself setting up Celery workers to understand how they behave makes things different. I suspect the only solution to issue of restarts is Celery. This in general is going to be the same no matter what WSGI server one uses.
Also need to confirm 'instance_id' setting, plus what WSGIPassAuthorization is being relied on for, as later I haven't needed yet, but then I haven't used the REST API yet.
At the end of what I am working on I should have a nice surprise you all may be interested to see. :-)
Comment by Mads Kiilerich, on 2016-04-03 21:46
Celery is only used for long-running tasks so they can be run async outside WSGI. Without Celery there will be more "slow" responses, but I don't think Celery is relevant for anything related to what we are discussing here. But ok - I understand your scope is bigger than what is said here ;-)
And just to make it clear: The problem I refer to is when the request is long running because the response is GBs of data and the bandwidth is limited. There is no way that can be offloaded to celeryd.
'instance_id' is an old odd thing that has been dropped on the default branch. It is only about notifying worker process (if you have more than one) about when caches should expire. I also don't think that is relevant for anything here. Also in 0.3.1 it should just work fine with the default value of '*'.
AFAIK WSGIPassAuthorization is used because hg/git protocol requests use http authentication and we (generally) don't want the web server to process that but just forward it to the wsgi process.
"The API" is "JSON RPC" - not so much REST. I don't think there is anything special authentication there.
Anyway, this is a general discussion and not just an apache/mod_wsgi/kallithea issue - perhaps move it to the mailing list.
Comment by Graham Dumpleton, on 2016-04-04 03:25
Celery would though be used when creating a new repo and asking to clone it from somewhere else though wouldn't it. That is what I was thinking.
The problem of long running client requests for clone is indeed separate, and it is going to be a problem with any Python web server you use. There is no simple solution to get around such issues, except not to restart the servers unless you really need to.
Personally what I would be doing is using separates web server instances just to handle git/hg client interactions. That way the potentially long running and I/O bound requests are in separate processes where you can better tune what the server parameters are. Problem is that the choice of URL paths used in Kallithea makes that difficult. This is because Kallithea mixes the git/hg endpoint URLs in amongst the web page URLs.
What I mean by this, is that all git/hg client requests are not all under a single sub URL. Instead for a clone it makes requests against:
"GET /wsgi-hello-world/info/refs?service=git-upload-pack HTTP/1.1" 200 205 "POST /wsgi-hello-world/git-upload-pack HTTP/1.1" 200 3583
This means that you have to use somewhat complicated regular expression pattern matching to identify git/hg client requests and redirect them to a different server in a front end, because the repo is the first part of the URL.
You would have had a much better system if all client accesses where under '/_client'. Thus:
"GET /_client/wsgi-hello-world/info/refs?service=git-upload-pack HTTP/1.1" 200 205 "POST /_client/wsgi-hello-world/git-upload-pack HTTP/1.1" 200 3583
That way a front end router can match on just prefix of '/_client' and much more efficiently send them to different backend instances tuned properly for the longer running requests they would receive.
In the stuff I am playing with, which would allow really easy cloud hosting of Kallithea, the existence of '/_client' would have allowed me to create a much more efficient and performant deployment, where the number of instances handling client interaction could be scaled separate to the web ui parts. Routers in the cloud environment don't give you full control on path based routing so prefix matching it all you get.
Sort of wish there was a way of easily configuring through the '.ini' file that such a switch in URL paths could be affected so that cloud based hosting could be done better.
Comment by domruf, on 2016-04-04 12:45
I think the right thing to do would be to use the User-Agent header instead of the path when you want run one instance for hg/git clients and one for the web interface.
Comment by Graham Dumpleton, on 2016-04-04 12:56
You are assuming one has control over the router to a degree to be able to do that. The cloud infrastructure am dealing with can only deal with path based routing using a URL prefix.
Comment by Mads Kiilerich, on 2016-04-04 23:15
Yes, if celery is available, it should be used for cloning repositories. That gives a better user experience and avoids a "slow pull". The clone happening behind the scene will however still be long running, so that will only reduce the amount of slow http requests in the world - not avoid them.
Regarding restarting a web server while preserving long running requests/responses: There might not be a "simple" solution, but it doesn't sound like it has to be that complicated?
A web server could launch new worker processes and hand new requests to the new worker processes while the old worker processes finish the requests they already got. With enough wrapping that could even be done at socket level by letting the new server share the port with the old one and tell the old one to stop accepting new connections. Or it could be done with "iptables" or HA/loadbalancers in front of multiple web server instances.
I guess mod_wsgi could do something similar by launching new worker processes while allowing the old ones to finish the requests they already got? Or is that already what happens if shutdown-timeout is set high enough (and I avoid apache restarts)?
Yes, it is a bit confusing that web browsers and Mercurial/Git clients can use the same URL. But it is also elegant and user friendly.
In a way, these two parts of the server are very unrelated. The only "link" between them is the Clone URL shown in the UI (and in a few other places). It can easily be hacked to point at different URLs (or presumably in your case: container "mount points"?). It could even be upstreamed as a variant of the (unfortunately undocumented) canonical_url .ini setting (a little bit like the odd gist_alias_url setting).
I guess you also easily could create a WSGI middleware that would dispatch based on the HTTP_ACCEPT of application/mercurial - see simplehg.py and simplegit.py .
In another way they are very related. I do not see much value in separating these two functions. Most protocol requests are short and fast ... and some PR pages can unfortunately also be big. They all require the same database access for access control and both require write access to the repositories for pushing and editing through the web.
(I would see more value in having some affinity from repositories to worker processes so they could reuse caches, and perhaps even abuse keepalive to keep a dedicated worker process/thread around so it could cache "everything" and efficiently process all the low level http requests that are a part of a (Mercurial) pull.)
Comment by domruf, on 2016-04-12 10:18
What about the clone URL scheme?
Under Admin->Settings->Visual you can define the scheme of the clone URLs. So you can run 2 kallithea instances 1 for the web interface and one for the git/hg clients. And in the URL scheme you configure a scheme that points to the second instance!?
Comment by Graham Dumpleton, on 2016-04-12 10:42
On first appearance that looks like it may do what I need. Will try playing with that. Thanks.
Comment by Graham Dumpleton, on 2016-04-12 22:18
On a quick test that doesn't appear to work. Yes it changes the displayed name so I see:
on the repos summary, but then when do clone it fails:
$ git clone http://kallithea-snakes.apps.10.2.2.2.xip.io/_client/hello Cloning into 'hello'... fatal: repository 'http://kallithea-snakes.apps.10.2.2.2.xip.io/_client/hello/' not found
At the same path, the original path before changing the setting still works:
$ git clone http://kallithea-snakes.apps.10.2.2.2.xip.io/hello Cloning into 'hello'... remote: Counting objects: 3, done. remote: Total 3 (delta 0), reused 0 (delta 0) Unpacking objects: 100% (3/3), done. Checking connectivity... done.
Comment by Mads Kiilerich, on 2016-04-13 00:42
Did you configure a separate instance of Kallithea under _client/ ?
Comment by Graham Dumpleton, on 2016-04-13 00:45
Okay, maybe I am misunderstanding how that works. I assumed that it would restructure URLs within the once instance. I believe it should be a simple matter for me to start up separate instance at same time with different mount point so will try again. Thanks.
Comment by Graham Dumpleton, on 2016-04-13 02:33
This approach actually provides two options, which is good.
The first is what I was looking at above in that one could use a URL prefix:
{scheme}://{user}@{netloc}/_client/{repo}
Then mount additional instances under the sub URL mount point.
In the system I am using I can do that, but then the URL for that then looks a bit messy though.
The alternative and which I am using in my test for now is to use an alternate hostname for the client accesses, thus:
{scheme}://{user}@repos-{netloc}/{repo}
With the split that means I can now configure the Apache/mod_wsgi instances that host the UI interface differently to those handling client accesses. Thus the one handling clients could maybe use multithreading more if turns out it is principally I/O bound. I can also have different numbers of instances of each, so can scale them up independently based on usage.
My dashboard right now therefore looks like:
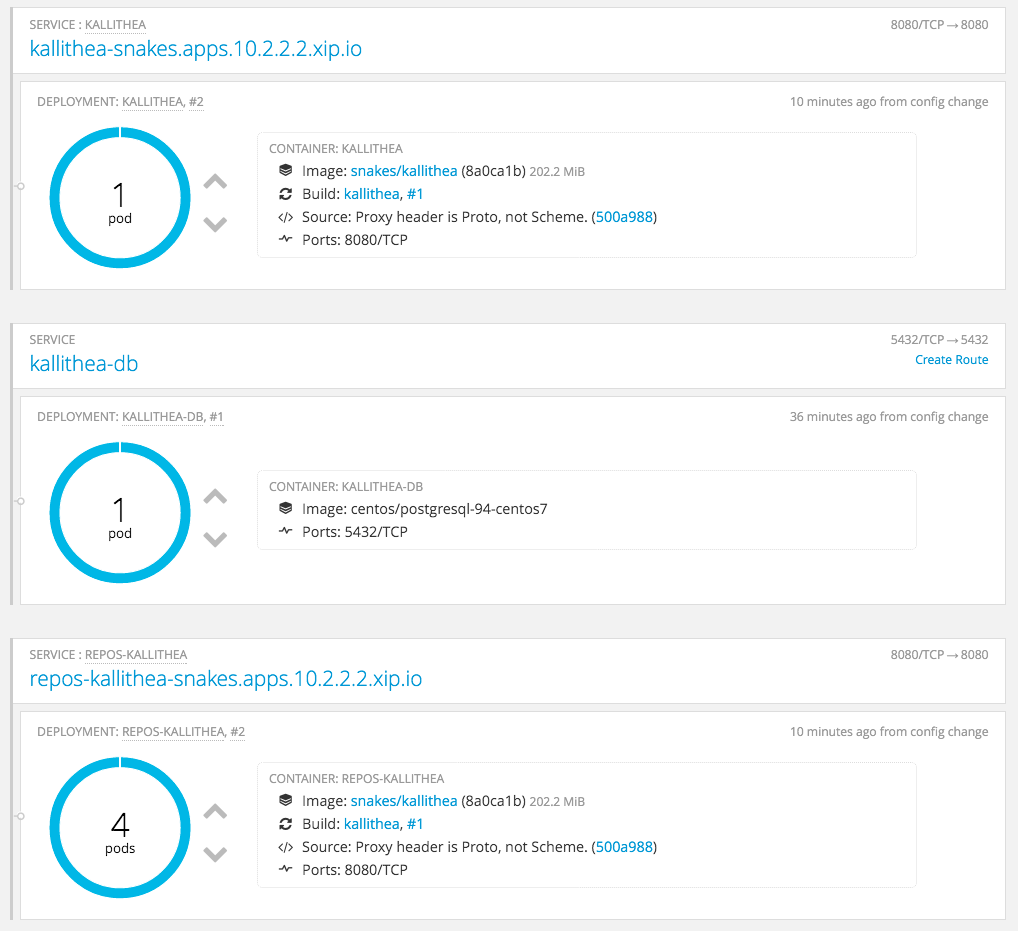
Thanks again for your help. Given me more to think about.
Comment by Mads Kiilerich, on 2016-05-05 14:03
The documentation issues have been fixed in 0.3.2. Thanks for helping out!
Please continue the other discussion on the mailing list.